问题描述
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数 (即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
假定 BST 满足如下定义:
结点左子树中所含节点的值 小于等于 当前节点的值
结点右子树中所含节点的值 大于等于 当前节点的值
左子树和右子树都是二叉搜索树
示例 1:
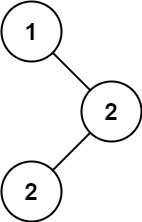
输入 :root = [1,null,2,2]输出 :[2]
示例 2:
输入 :root = [0]输出 :[0]
提示:
树中节点的数目在范围 [1, 104] 内
-105 <= Node.val <= 105
进阶 :你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
中序遍历
核心思路
如果不是二叉搜索树,最直观的方法一定是把这个树都遍历了,用map统计频率,把频率排个序,最后取前面高频的元素的集合。
不过对于搜索树,中序遍历是有序的。遍历有序数组的元素出现频率,从头遍历,那么一定是相邻两个元素作比较,然后就把出现频率最高的元素输出就可以了。
顺序扫描中序遍历序列,用 base \textit{base} base count \textit{count} count maxCount \textit{maxCount} maxCount answer \textit{answer} answer
首先更新 base \textit{base} base count \textit{count} count base \textit{base} base count \textit{count} count base \textit{base} base count \textit{count} count
然后更新 maxCount \textit{maxCount} maxCount count = m a x C o u n t \textit{count} = maxCount count = m a x C o u n t base \textit{base} base base \textit{base} base answer \textit{answer} answer
如果 count > m a x C o u n t \textit{count} > maxCount count > m a x C o u n t base \textit{base} base maxCount \textit{maxCount} maxCount count \textit{count} count answer \textit{answer} answer base \textit{base} base answer \textit{answer} answer update \text{update} update
然后,我们考虑不存储这个中序遍历序列。 如果我们在递归进行中序遍历的过程中,访问当了某个点的时候直接使用上面的 update \text{update} update
code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Solution {public : vector<int > answer; int base, count, maxCount; void update (int x) if (x == base) { ++count; } else { count = 1 ; base = x; } if (count == maxCount) { answer.push_back (base); } if (count > maxCount) { maxCount = count; answer = vector<int > {base}; } } void dfs (TreeNode* o) if (!o) { return ; } dfs (o->left); update (o->val); dfs (o->right); } vector<int > findMode (TreeNode* root) { dfs (root); return answer; } };
Morris 中序遍历
核心思路
用 Morris 中序遍历的方法把中序遍历的空间复杂度优化到 O ( 1 ) O(1) O ( 1 ) O ( 1 ) O(1) O ( 1 ) right \textit{right} right right \textit{right} right right \textit{right} right
Morris 中序遍历的一个重要步骤就是寻找当前节点的前驱节点,并且 Morris 中序遍历寻找下一个点始终是通过转移到 right \textit{right} right
如果当前节点没有左子树,则遍历这个点,然后跳转到当前节点的右子树。
如果当前节点有左子树,那么它的前驱节点一定在左子树上,我们可以在左子树上一直向右行走,找到当前点的前驱节点。right \textit{right} right right \textit{right} right
code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class Solution {public : int base, count, maxCount; vector<int > answer; void update (int x) if (x == base) { ++count; } else { count = 1 ; base = x; } if (count == maxCount) { answer.push_back (base); } if (count > maxCount) { maxCount = count; answer = vector<int > {base}; } } vector<int > findMode (TreeNode* root) { TreeNode *cur = root, *pre = nullptr ; while (cur) { if (!cur->left) { update (cur->val); cur = cur->right; continue ; } pre = cur->left; while (pre->right && pre->right != cur) { pre = pre->right; } if (!pre->right) { pre->right = cur; cur = cur->left; } else { pre->right = nullptr ; update (cur->val); cur = cur->right; } } return answer; } };